This morning I thought I would focus a little bit of love on NectarEngine and, well, that's exactly what I did.
So, I went through it and made sure all the tests pass first, I updated the test cases to make use of the block data from lite nodes as that is what most people seem to be running.
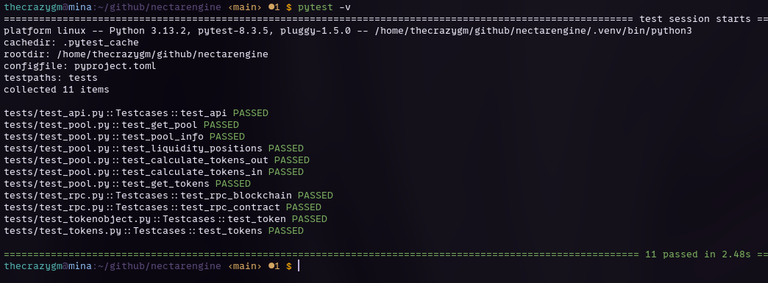
Now, some eagle eyed person might notice among those tests are things that mention the liquidity pool!
I have added the classes for Liquidity pools and Pool objects, as well as many methods to use with them.
from nectarengine.pool import LiquidityPool
# Initialize the LiquidityPool instance
pool = LiquidityPool()
# Get the SWAP.HIVE:INCOME pool
income_pool = pool.get_pool("SWAP.HIVE:INCOME")
if income_pool:
print(f"Pool Info: {income_pool}")
# Get liquidity positions
positions = income_pool.get_liquidity_positions()
print("\nLiquidity Positions:")
for position in positions:
print(f"Account: {position['account']}, Shares: {position['shares']}")
# Get pool price
price = income_pool.calculate_price()
print(f"\nPool Price: {price}")
else:
print("SWAP.HIVE:INCOME pool not found")
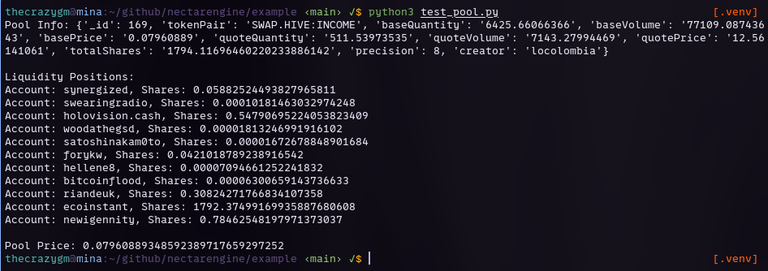
I haven't went through the setup for readthedocs yet, but the html documentation is in the repo, for those wanting to give it a go. I need to update the kanban with the progress, and give it a couple more tests, I've tested most everything, need to test the token swap, but I'm fairly confident it works, and if it doesn't, I'll get right on it.
I did want to share that NectarEngine is also getting love, and this isn't all about beem HiveNectar.
As I said the other day:
Maybe this will help someone, maybe it won't. But it is the kind of stuff I do daily just because I enjoy doing it.
Perhaps you will support our vision:
Proposal 339: A modular open-source development framework with critical library maintenance.
As always,
Michael Garcia a.k.a. TheCrazyGM





